
HoloClean:
Weakly Supervised Data Repairing
Post by Theo Rekatsinas, Ihab Ilyas, and Chris Ré
Data cleaning and repairing account for about 60% of the work of data scientists.
Noisy and erroneous data is a major bottleneck in analytics. Data cleaning and repairing account for about 60% of the work of data scientists. To address this bottleneck, we recently introduced HoloClean, a semi-automated data repairing framework that relies on statistical learning and inference to repair errors in structured data. In HoloClean, we build upon the paradigm of weak supervision and demonstrate how to leverage diverse signals, including user-defined heuristic rules (such as generalized data integrity constraints) and external dictionaries, to repair erroneous data.
HoloClean has three key properties:
It is the first holistic data cleaning framework that combines a variety of heterogeneous signals, such as integrity constraints, external knowledge, and quantitative statistics, in a unified framework.
It is the first data cleaning framework driven by probabilistic inference. Users only need to provide a dataset to be cleaned and describe high-level domain specific signals.
It can scale to large real-world dirty datasets and perform automatic repairs that are two times more accurate than state-of-the-art methods.
HoloClean can fix diverse errors in structured datasets, ranging from conflicting and misspelled values to outliers and null entries.All too often, the data collected by companies, organizations, and researchers is filled with mistakes, errors, and incomplete values. This is referred to as dirty data, and it can represent a formidable obstacle to downstream applications. Take for example a snippet from the Food Inspections dataset published by the City of Chicago:
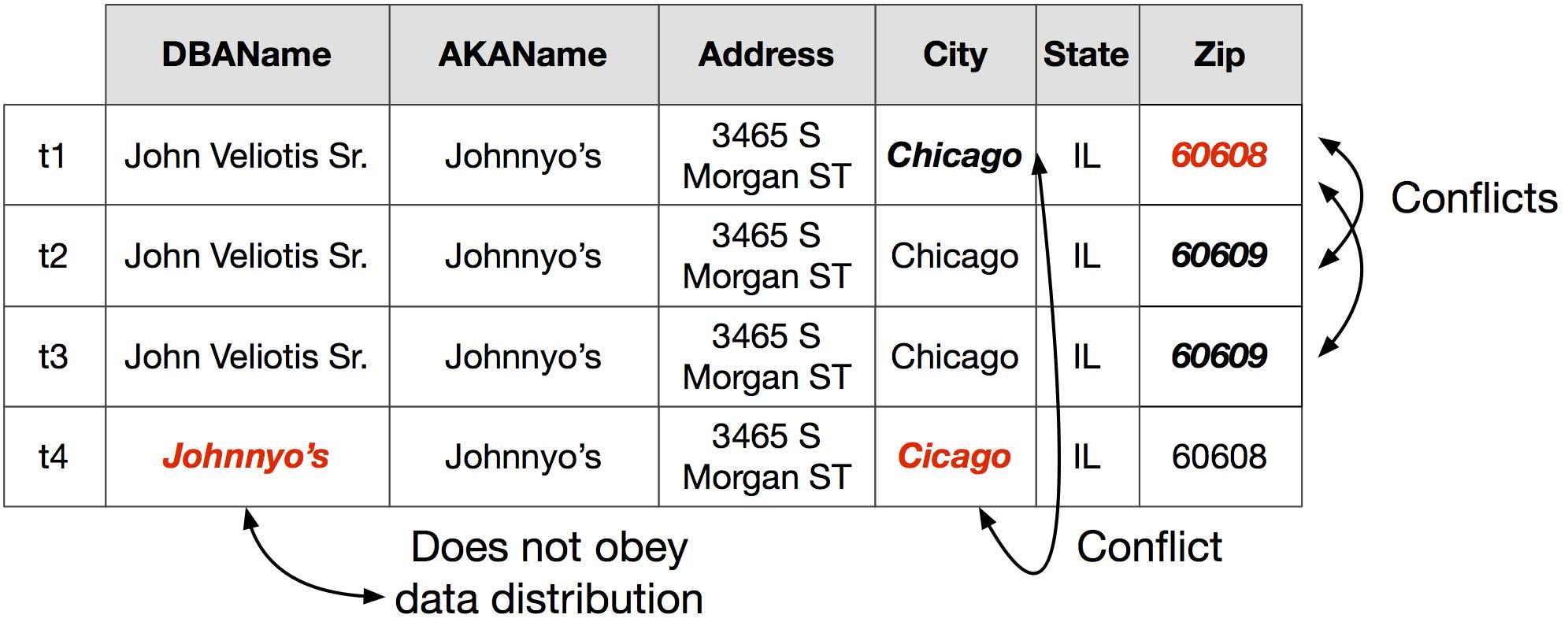
In HoloClean, we focus on structured datasets such as the one shown above. Our goal is to identify and repair all cells whose initial, observed value is different from their true value, which is unknown. We term these erroneous cells. Given the above, data cleaning is separated into two tasks: (i) error detection, whose goal is to identify erroneous cells, and (ii) data repairing, whose goal is to infer the true value of detected erroneous cells.
Data cleaning is a statistical learning and inference problem.
HoloClean casts data cleaning as a statistical learning and inference problem. Each cell of an input, dirty dataset is associated with a random variable. That random variable can either have a fixed value if the corresponding cell was not detected to be erroneous, or an unknown value, if the corresponding cell was detected to be erroneous. HoloClean uses random variables with fixed values as training data to learn a probabilistic model for repairing erroneous cells, whose random variables have unknown values.
In HoloClean, users only need to specify high-level assertions that capture their domain-expertise with respect to invariants that the input data needs to satisfy. No other supervision is required!
How can we train a probabilistic model for data cleaning efficiently? As with any other large-scale machine learning problem, users cannot afford to iterate over all cells in a dataset with millions of tuples to identify erroneous cells and suggest repairs. This is where weak supervision shines!
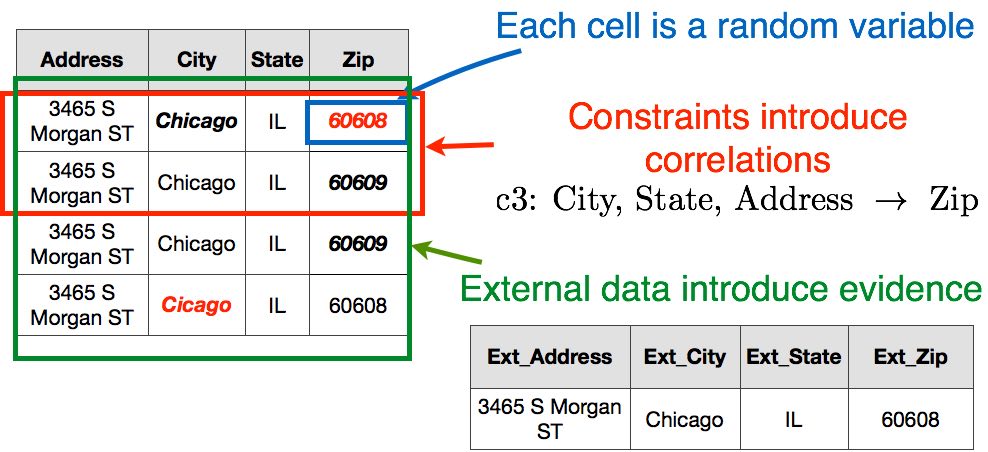
HoloClean unifies heterogeneous weak signals that provide evidence on the correct value of structured data to detect and repair errors.HoloClean leverages a variety of weak signals to address error detection and data repairing:
In HoloClean, users can specify denial constraints, a general form of integrity constraints, to detect tuples that report conflicting information. For example, in the Food Inspections dataset, the functional dependency City, State, Address → Zip, can be used to identify that the information provided by Tuple t1 is in conflict with the information of Tuples t2 and t3. Denial constraints are high-level first-order logic rules that capture the user's domain-expertise. These rules can be specified by the user or even discovered automatically.
Users also have the option to use external datasets or dictionaries and specify high-level rules that match the data provided by a trusted external dataset to the input dataset to be cleaned.
HoloClean uses state-of-the-art outlier detection methods that leverage quantitative statistics to find cells whose value does not obey overall distributional properties of the input data. Outlier detection is run automatically and requires no input by the user.
Denial constrains introduce correlations over sets of random variables. For example, if the random variables for cells Address, City, and State in Tuples t1 and t2 have matching values then the random variables for t1.Zip and t2.Zip should take the same value.
External data determine priors on the correct value of different cells. For example, the fact that address "3465 S Morgan St, Chicago, IL" is assigned to Zip Code "60608" in an external dataset provides evidence that the initially observed Zip Code of "60609" is wrong.
Finally, HoloClean uses the available labeled data (generated via the weak signals described above) to learn a series of quantitative statistics over the input data (e.g., co-occurrence statistics over pairs of attribute values). Quantitative statistics are used to form priors over the assignment of random variables that correspond to erroneous cells.
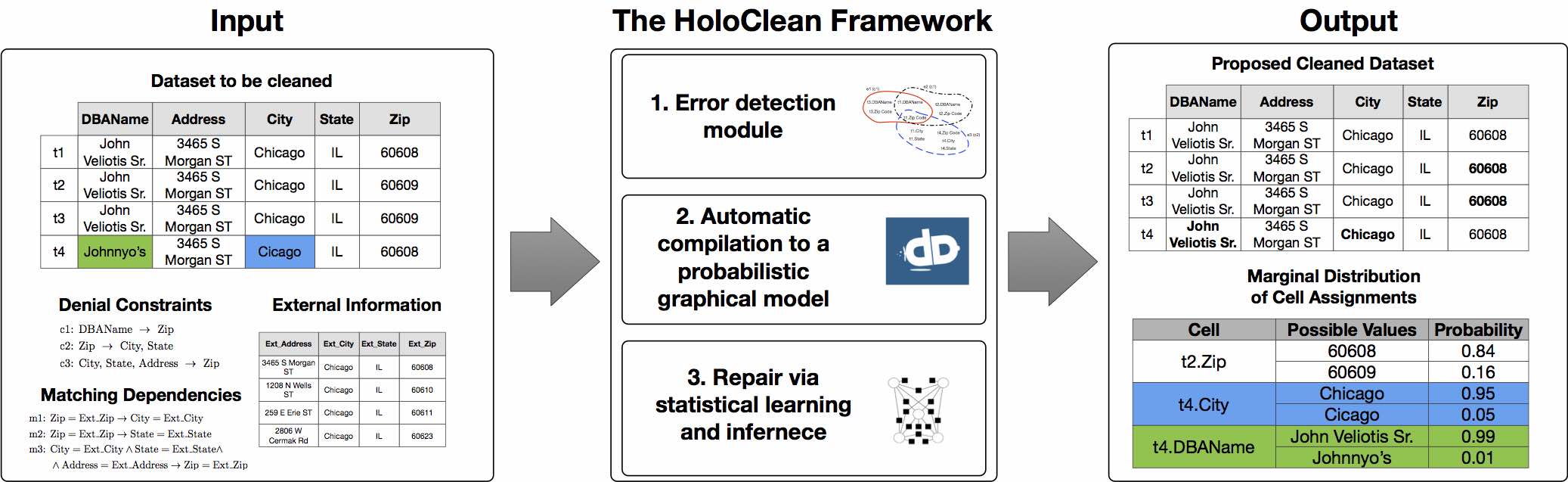
Overall, HoloClean is a data cleaning framework that takes as input a dirty dataset, a collection of integrity constraints, and potentially a collection of external data and forms a probabilistic model for data cleaning. HoloClean builds upon DeepDive, our in-house general-purpose inference engine, to execute learning and inference over its model. For each random variable HoloClean estimates its maximum a posteriori assignment as well as the marginal distribution over the values in its domain. The latter can be used to identify repairs with low confidence and solicit additional user-feedback in a principled manner.
In our paper we evaluate HoloClean over a variety of real-world datasets, including the Food Inspections dataset presented above. We compare HoloClean with various state-of-the-art data cleaning methods. All prior methods are designed to use each of the signals presented above in isolation. On the other hand, due to the flexibility and extensibility of probabilistic models, HoloClean can combine all signals in a unified framework.
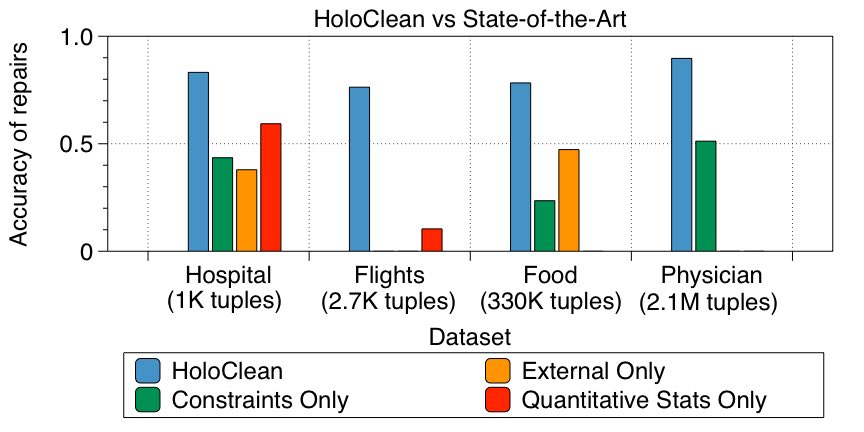
In our experiments we find that HoloClean finds data repairs with an average precision of ~90% and an average recall of above 76% across a diverse array of datasets exhibiting different types of errors. This yields an average F1 improvement of more than 2x against state-of-the-art methods.
Hard constraints (e.g., integrity constraints) lead to complex and non-scalable repairing models.
The main technical challenge in HoloClean is scaling inference over the probabilistic model used for data cleaning. It is well-known that inference in the presence of constraints is #P-complete. This is because during inference one needs to consider all possible joint assignments over sets of random variables that are correlated. For example, consider the dataset shown in the figure below:

The user-specified integrity constraint shown in the Example introduces a correlation across the four random variables corresponding to the cells of Tuples t1 and t3. If we naively encode this correlation by converting the integrity constraint to a first-order logic constraint, we need to enumerate all possible assignments over these four random variables. It is easy to see that for complex constraints and data cleaning instances with millions of tuples and random variables with large domains this naive approach does not scale.
HoloClean relaxes constraints over sets of data cells to simple features over individual data cells. This gives a scalable repairing model with independent random variables alone.
To ensure scalability, HoloClean applies integrity constraints over the input dataset to identify tuples that provide conflicting information and uses integrity constraints to learn features over the random variables associated with the cells corresponding to these tuples. The final probabilistic model generated by HoloClean corresponds to a voting model over independent random variables that ensures the local consistency of the values assigned to different cells.
In our paper, we empirically find that when there is sufficient redundancy in observing the correct value of cells in a dataset, HoloClean's approximate model obtains more accurate repairs and is more robust to misspecification of the domain of random variables in its probabilistic model.
A few things we are excited about:
We are actively exploring the connections between HoloClean's relaxed model and other structured prediction tasks. Specifically, we are focusing on cases where globally consistent constraints can be replaced with locally consistent priors due to redundancy in the observed data. In fact, trading off constraints for features has been an open area of study in the area of probabilistic inference over structured models.
We are working on combining HoloClean with Snorkel, our new data-programming engine, to provide users with an interactive way of specifying and revising weak signals for constructing data cleaning models.